Flume 学习笔记
引子
(第一篇github博客成功发表,感谢hubpress!)
缘起:虽然地铁上总是大部分时间都用来看头条,玩游戏,但是微信上的架构师订阅号总能偶尔让人眼前一亮,什么Flume,Kafka,Thrift,ZooKeeper时不时敲打着我的羞耻心、上进心和求知欲。作为我这个级别的人,是不是得看看,混个脸熟?……但也仅仅是脸熟而已。
直到最近,发现很难躲过去,项目需要处理大量的日志数据,发现几点目前采用的MongoDB MapReduce方案的问题: 虽然MongoDB的MapReduce虽然能够利用分片位置提高速度,但是需要数据库进程级别的锁,难以在不影响日志写入的情况下,对数据进行分析处理,所以需要拆分。
但MongoDB的MapReduce要求源数据和输出数据在同一个数据库,要解决数据分析对产品环境的影响,就要求我们数据再存一份数据作为源给MapReduce用。一开始想到的是用副本集解决多份数据的问题,用Primary来接受写入的数据,Secondary来做MapReduce的数据源,但是由于MongoDB MapReduce要求源数据和输出数据在同一个数据库,“同一个数据库”,意味着要往Secondary写数据,这是MongoDB不允许的。难道要自己写个机制把数据从日志表同步到MapReduce的数据库吗?
考虑到MongoDB的写入速度,恐怕用来存储日志不太适合,直到看过更多前辈的文章,发现一般的方案是用Flume。
Flume的作用是收集日志,有各种好处,高可用,可扩展,可靠,高性能,分布式,重要的是,数据写到HDFS,数据分析有着落了。
正文
*安装
安装hadoop
sudo addgroup hadoop
sudo adduser --ingroup hadoop hduser
sudo adduser hduser sudo
su hduser
ssh-keygen -t rsa -P ""
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
ssh localhost
exit
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
tar xvzf hadoop-2.7.2.tar.gz
sudo mkdir /usr/lib/hadoop
sudo mv hadoop-2.7.2 /usr/lib/hadoop/
sudo chown -R hduser:hadoop /usr/lib/hadoop安装Flume
先是Flume的安装,可以参考 http://hadooptutorial.info/apache-flume-installation/
nu@node:~$ wget http://mirror.bit.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
nu@node:~$ sudo mkdir /usr/lib/flume
nu@node:~$ sudo chmod -R 777 /usr/lib/flume
nu@node:~$ cp apache-flume-1.6.0-bin.tar.gz /usr/lib/flume/
nu@node:~$ cd /usr/lib/flume/
nu@node:/usr/lib/flume$ tar -xzf apache-flume-1.6.0-bin.tar.gz
nu@node:/usr/lib/flume$ ls
apache-flume-1.6.0-bin apache-flume-1.6.0-bin.tar.gz
nu@node:/usr/lib/flume$添加到~/.bashrc
### Flume Home Directory
export FLUME_HOME="/usr/lib/flume/apache-flume-1.6.0-bin"
export FLUME_CONF_DIR="$FLUME_HOME/conf"
export FLUME_CLASSPATH="$FLUME_CONF_DIR"
export PATH="$FLUME_HOME/bin:$PATH"
### Flume Home Directory endnu@node:/usr/lib/flume/apache-flume-1.6.0-bin/conf$ cp flume-env.sh.template flume-env.sh
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin/conf$ vi flume-env.sh修改flume-env.sh添加:
# export JAVA_HOME=/usr/lib/jvm/java-6-sun
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64运行flume-ng测试:
nu@node:~$ flume-ng --help*简单示例
点击 https://flume.apache.org/FlumeUserGuide.html 进行更深入的了解。
示例1
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin/conf$ vi example.conf把下面的内容添加进去:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1nu@node:~$ cd /usr/lib/flume/apache-flume-1.6.0-bin
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin$ flume-ng agent --conf conf --conf-file conf/example.conf --name a1 -Dflume.root.logger=INFO,console这里,如果你是按照 https://flume.apache.org/FlumeUserGuide.html 的指导,用下面的命令:
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console如果你在flume conf目录下运行这个命令,他会提示错误:
Warning: JAVA_HOME is not set!
Info: Including Hive libraries found via () for Hive access
+ exec /usr/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp 'conf:/usr/lib/flume/apache-flume-1.6.0-bin/lib/*:/lib/*' -Djava.library.path= org.apache.flume.node.Application --conf-file example.conf --name a1
log4j:WARN No appenders could be found for logger (org.apache.flume.lifecycle.LifecycleSupervisor).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.即使你把JAVA_HOME设置好,log4j的错误依然还在。后来发现 --conf conf是指定配置文件的目录,所以要让上面的命令运行起来,需要在conf的上一层目录运行命令,并且example.conf要在那个目录下,或者也在conf下,而用下面的命令:
bin/flume-ng agent --conf conf --conf-file conf/example.conf --name a1 -Dflume.root.logger=INFO,console现在agent已经启动,再起一个terminal窗口,执行:
nu@node:~$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.输入“Hello world!”,回车:
Hello world!
OK在agent执行窗口会看到:
2016-05-13 14:12:11,592 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }*第三方插件
插件目录可以加到flume-env.sh中的FLUME_CLASSPATH,或者直接把插件装到plugins.d目录下面。 每个插件目录可以有三个子目录: lib, libext, native
Avro RPC
用下面命令发送日志文件到Flume:
$ bin/flume-ng avro-client -H localhost -p 41414 -c conf -F /usr/logs/log.10插件比较多,就不一个一个学了,主要看看如何把数据存入hdfs。
*Multi-agent flow
Consolidation (合并)
Multiplexing (多工?)
*把数据存入hdfs
这是首要目标!
推荐一篇博客:http://scu.qfboys.com/blog/storage/flume-hdfs.html
配置两个agent: netcat_avro.conf
# list the sources, sinks and channels for the agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# set channel for source
a1.sources.r1.channels = c1
# set channel for sink
a1.sinks.k1.channel = c1
# properties of r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# properties of c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# properties of k1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 10001avro_hdfs.conf
# list the sources, sinks and channels for the agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# set channel for source
a1.sources.r1.channels = c1
# set channel for sink
a1.sinks.k1.channel = c1
# properties of r1
a1.sources.r1.type = avro
a1.sources.r1.bind = localhost
a1.sources.r1.port = 10001
# properties of c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# properties of k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://localhost/flume/webdata运行avro_hdfs:
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin$ flume-ng agent --conf conf --conf-file conf/avro_hdfs.conf --name a1 -Dflume.root.logger=INFO,console看到这个错误:
2016-05-13 23:18:04,801 (conf-file-poller-0) [ERROR - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:145)] Failed to start agent because dependencies were not found in classpath. Error follows.
java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType
at org.apache.flume.sink.hdfs.HDFSEventSink.configure(HDFSEventSink.java:239)
at org.apache.flume.conf.Configurables.configure(Configurables.java:41)
at org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:413)
at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:98)
at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:140)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask$Sync.innerRunAndReset(FutureTask.java:351)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1110)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:603)
at java.lang.Thread.run(Thread.java:722)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.io.SequenceFile$CompressionType
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:423)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:356)
... 13 more谷歌到 http://scu.qfboys.com/blog/storage/flume-hdfs.html ,把各个jar考到flume/lib或加到FLUME_CLASSPATH里。注意由于hadoop版本不同,里面列的几个文件,你的版本里可能不是都有,根据情况选择对应的新版替换掉。对应于我的环境,FLUME_CLASSPATH的设置是:
FLUME_CLASSPATH="/usr/lib/hadoop/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar:/usr/lib/hadoop/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar:/usr/lib/hadoop/hadoop-2.7.2/share/hadoop/common/lib/commons-codec-1.4.jar:/usr/lib/hadoop/hadoop-2.7.2/share/hadoop/common/lib/commons-configuration-1.6.jar:/usr/lib/hadoop/hadoop-2.7.2/share/hadoop/common/lib/jets3t-0.9.0.jar:/usr/lib/hadoop/hadoop-2.7.2/share/hadoop/common/lib/commons-httpclient-3.1.jar:/usr/lib/hadoop/hadoop-2.7.2/share/hadoop/common/lib/hadoop-auth-2.7.2.jar:/usr/lib/hadoop/hadoop-2.7.2/share/hadoop/common/lib/htrace-core-3.0.4.jar"要找到你的对应文件的位置,使用find:
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin$ find /usr/local/hadoop/ -name commons-codec*
/usr/local/hadoop/share/hadoop/hdfs/lib/commons-codec-1.4.jar
/usr/local/hadoop/share/hadoop/common/lib/commons-codec-1.4.jar
/usr/local/hadoop/share/hadoop/kms/tomcat/webapps/kms/WEB-INF/lib/commons-codec-1.4.jar
/usr/local/hadoop/share/hadoop/tools/lib/commons-codec-1.4.jar
/usr/local/hadoop/share/hadoop/httpfs/tomcat/webapps/webhdfs/WEB-INF/lib/commons-codec-1.4.jar
/usr/local/hadoop/share/hadoop/yarn/lib/commons-codec-1.4.jar选择一个看起来合适的。
然后,再次运行
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin$ flume-ng agent --conf conf --conf-file conf/avro_hdfs.conf --name a1 -Dflume.root.logger=INFO,console再起一个terminal窗口,运行:
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin$ flume-ng agent --conf conf --conf-file conf/netcat_avro.conf --name a1 -Dflume.root.logger=INFO,console然后,再起一个窗口,运行:
nu@node:~$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Hellow world!
OK这个时候发现 avro_hdfs agent窗口报错:
2016-05-14 00:57:48,148 (SinkRunner-PollingRunner-DefaultSinkProcessor) [WARN - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:455)] HDFS IO error
java.net.ConnectException: Call From node/127.0.1.1 to localhost:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.GeneratedConstructorAccessor6.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:525)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731)
at org.apache.hadoop.ipc.Client.call(Client.java:1472)
at org.apache.hadoop.ipc.Client.call(Client.java:1399)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at $Proxy13.create(Unknown Source)这个错是因为当我根据 http://www.bogotobogo.com/Hadoop/BigData_hadoop_Install_on_ubuntu_single_node_cluster.php 安装hadoop的时候,配了端口。我们看看现在那个端口是多少,打开 /usr/local/hadoop/etc/hadoop/core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
</configuration>端口是54310,改一下avro_hdfs.conf:
a1.sinks.k1.hdfs.path = hdfs://localhost:54310/flume/webdata再启动 avro_hdfs agent, 按上面的步骤再测试一遍,仍然报错:
2016-05-14 23:30:22,559 (SinkRunner-PollingRunner-DefaultSinkProcessor) [WARN - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:455)] HDFS IO error
org.apache.hadoop.security.AccessControlException: Permission denied: user=nu, access=WRITE, inode="/flume/webdata":hduser:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:257)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:238)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:179)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6512)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6494)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkAncestorAccess(FSNamesystem.java:6446)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInternal(FSNamesystem.java:2712)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2632)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2519)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:566)这个是因为,hadoop运行在hduser用户下,当前帐户nu,没有权限,可以通过下面方式来验证:
nu@node:/usr/lib/flume/apache-flume-1.6.0-bin$ sudo su hduser
hduser@node:/usr/lib/flume/apache-flume-1.6.0-bin$ source /home/nu/.bashrc
hduser@node:/usr/lib/flume/apache-flume-1.6.0-bin$ flume-ng agent --conf conf --conf-file conf/avro_hdfs.conf --name a1 -Dflume.root.logger=INFO,console再次测试,打开 http://node.guest:50070/explorer.html#/flume/webdata 页面,发现梦寐以求的文件:
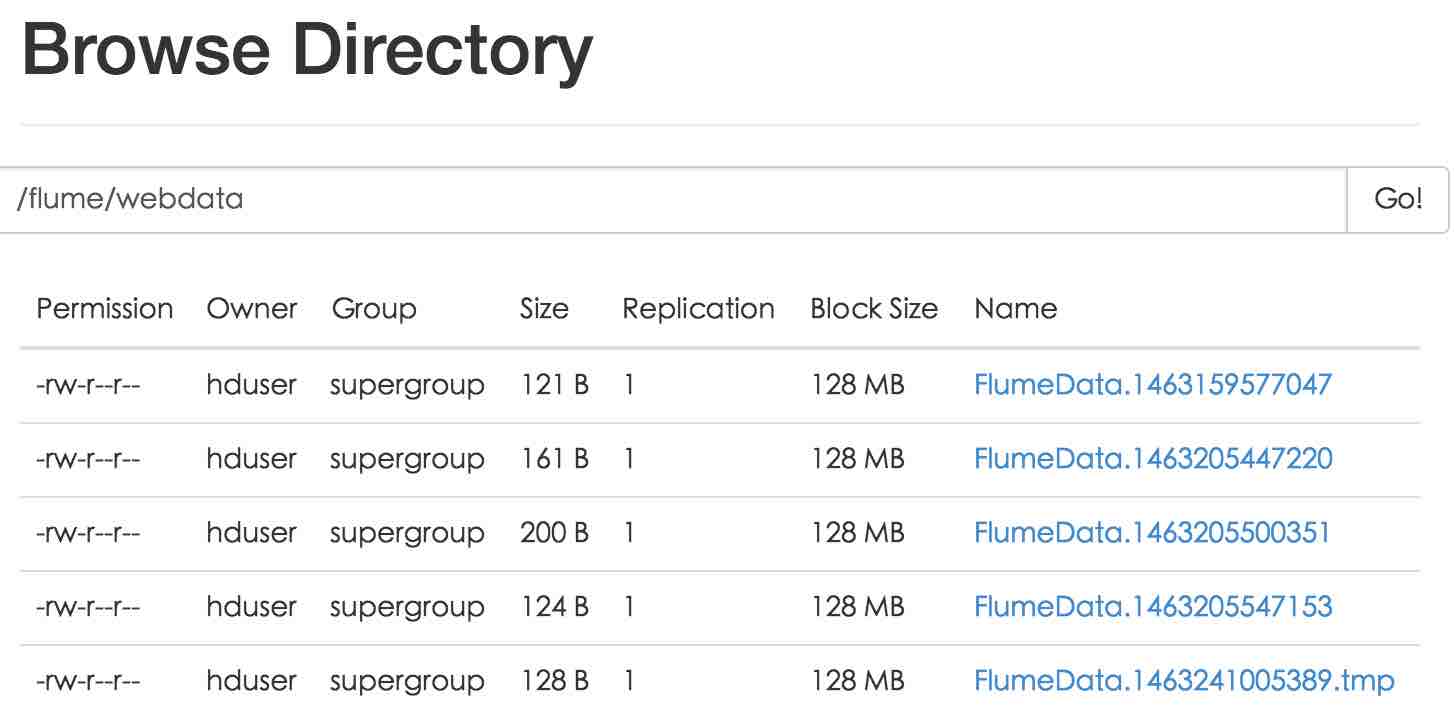
总结
MongoDB的MapReduce的局限,很难直接拿来实现大数据收集和分析。因此Flume的需求比较强烈和迫切。在上面的场景中使用Flume需要安装Java,Hadoop,Flume,然后实作了 netcat⇒logger, netcat⇒avro⇒hdfs的agent flow。
问题
最后的截屏发现一个问题,那些文件的Block Size 128MB,而文件本身只有100~200B,看起来非常浪费。hdfs大文件偏好的设计,Flume就没有考虑吗?希望后面有时间把这个问题搞清楚。